
Short Introduction
Biopython은 생물정보학 관련되어 파일 등을 더 쉽게 처리할 수 있는 모델을 포함하고 있으며, 효율적인 처리가 가능하다. 이러한 언어를 실제 연구실 상황 등에서 적용시킬 수 있도록 Biopython의 여러 모듈의 사용법을 공부하고, 이를 예시 파일 등에 적용시켜 봄으로서 모듈 사용법을 익힌다.
Content
프로젝트를 시작하게 된 계기는 책 ‘바이오파이썬으로 만나는 생물정보학’을 알게되면서 였다. 항상 FASTA 파일 등을 보면서 단순히 텍스트 형식이 아니라 편하게 볼 수 있는 방법이 있었으면 좋겠다고 생각하고 있었고, 바이오파이썬이 이러한 점을 채워줄 수 있을 것이라고 생각하여 스터디를 계획하였다.
이 프로젝트의 최종 목표는 파일을 읽고 다른 프로그램과 연계시키는 프로그램이었다.
프로젝트는 각 종류의 파일에 따라서 parsing을 진행하고, 사용자의 필요에 따라서 다른 프로그램(BLAST)나 Genbank 등으로 연결시키는 단계에 있으며, 만약 시간이 더 있었다면 웹페이지를 만들어 각 파일을 받아들이고, 선택적으로 사용자가 액션을 실행할 수 있도록 만들고 싶다.
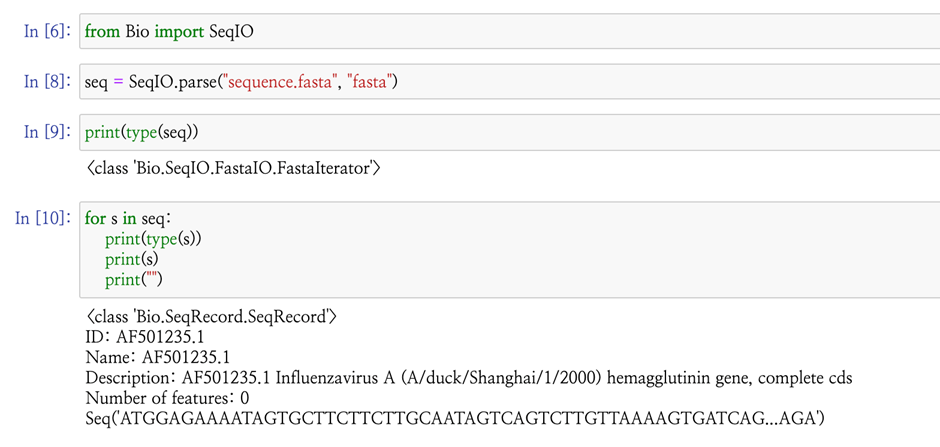
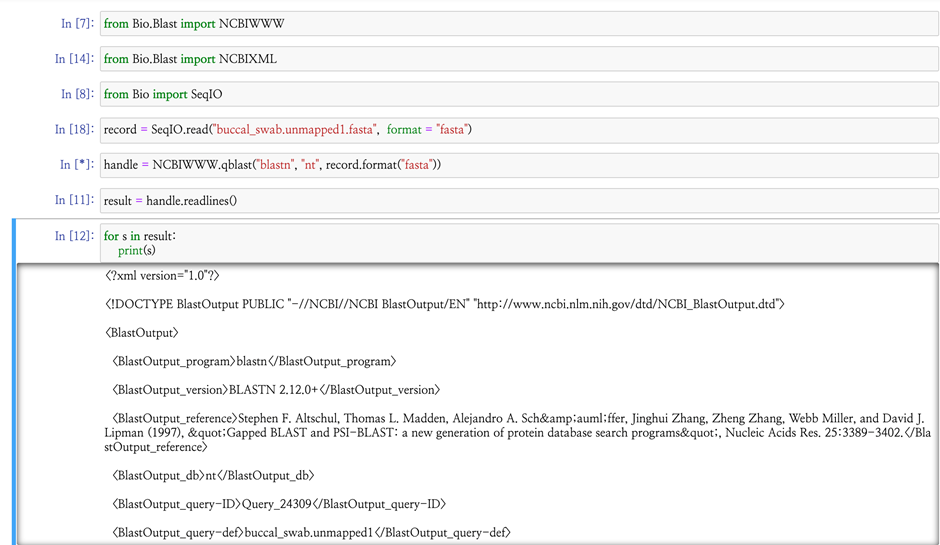
프로젝트를 진행하면서 sequence 객체를 다루고, FASTA, FASTQ, GenBank 파일을 읽고 염기서열을 parsing하고, 바이오파이썬으로 BLAST를 실행하였으며, NCBI 데이터베이스에서 읽어들인 정보를 찾아 연계하는 것까지 진행하였다.
프로젝트를 진행하면서 아쉬웠던 점이라고 하면 이러한 기능을 사용하는 방법을 익혔으나, 보다 쉽게 사용할 수 있도록 하나로 묶는 방법을 개발했으면 하는 아쉬움이 있다.
Attachments

About
본 글은 2021년도 2학기에 21 강다영 연구회원이 진행한 프로젝트입니다.